Jól ismert probléma, hogy egy összesen, egy total érték elfedi azokat az adatokat, mikből összeadódik. Megnézed egy termékcsoport profitabilitását, és látod, hogy szép nagy pozitív szám. Aztán ha elkezded nézegetni a termékeket, kiderül, hogy van benne néhány, ami igencsak rosszul teljesít – így már nem olyan szép a kép. Megalapozott üzleti döntéshez figyelni kell ezekre a részletekre is. Nade hogyan lehet ezt vizuálisan is megjeleníteni?
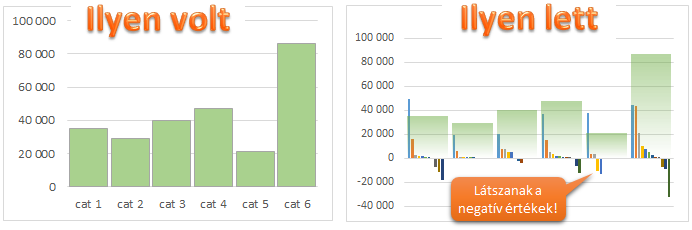
Nemrég az angol blogon írtam erről, megosztottam egy oszlop diagram megoldást, amit néhány egyszerű lépésben összeraktam. Roberto természetesen egy órán belül csinált egy másik megoldást, teljesen más megközelítésben. Az ő megoldását fogom most nektek bemutatni, részben azért, mert picit egyszerűbb, másrészt mert szépen illeszkedik a vízesés grafikonnál megtanult technikára.
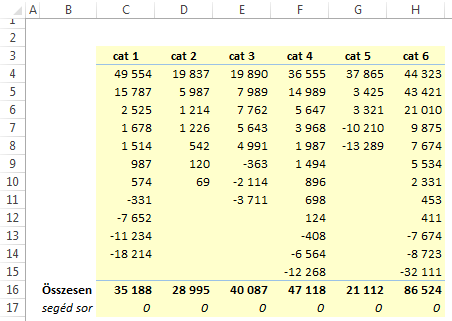
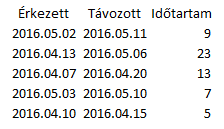
1. lépés: adattábla
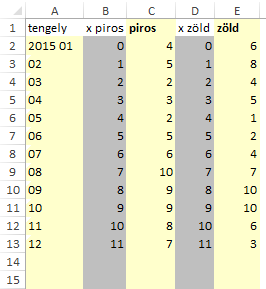
A termékcsoportok (kategóriák) szerepeljenek külön oszlopokban, alattuk a termék adatok sorba rendezve. A termék adatok nevére nincs szükség, azok nem fognak szerepelni a diagramon.
Alulra tegyél egy összesítő sort, alá pedig írj nullákat – ez egy segéd adatsorhoz kell majd.
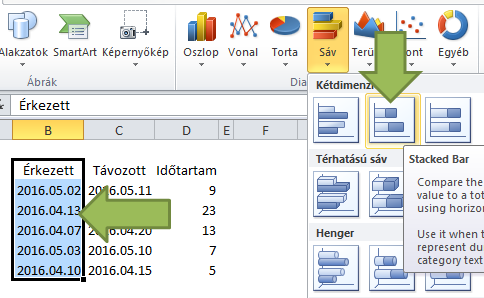
2. Alap diagram létrehozása
Jelöld ki az adattáblát, a feliratokkal együtt, de az összesen sor nélkül, és szúrj be oszlop diagramot.
Ezután meg kell cserélned a sorokat és oszlopokat: a Diagrameszközök menüben a Tervezés alatt találod a Sor/Oszlop váltása gombot (Chart tools / Design / Switch Row/Column)
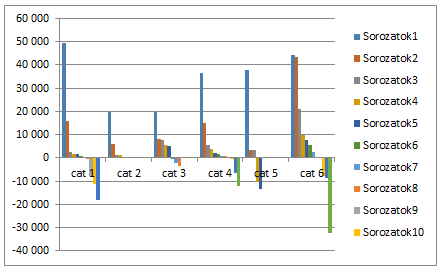
A jelmagyarázat félrevezető, ezért töröld ki.
3. Két új adatsor hozzáadása
Két új adatsorra lesz szükségünk. Egyik a termékcsoport összesen értékéből, a másikat a 0 sorból rakjuk fel. Mindkettőt vonal diagramtípussal fogjuk ábrázolni. Ezek közé kerülnek majd a termékcsoport oszlopok.
Tehát: a Diagrameszközök / Tervezés / Adatok kijelölése (Select Data) (vagy jobb klikk a diagramon). Válaszd a Hozzáadás gombot, jelöld ki az adatokat és adj egy nevet az adatsornak. (Nálam: top)
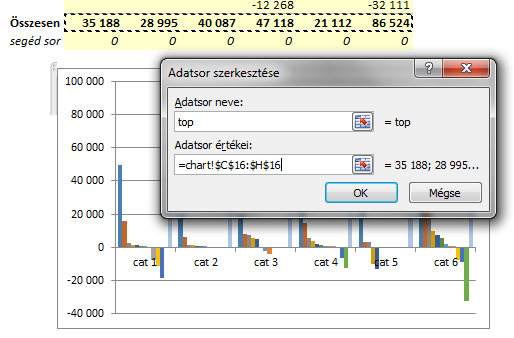
Ismételd meg ugyanezt még egyszer, és a 0-kat is add hozzá adatsorként a diagramhoz. (Nálam ez a bottom nevű lett.)
4. A két adatsor diagram típusának módosítása
Minkét utóbb hozzáadott adatsor diagram típusát vonalra módosítjuk. Jelöld ki az egyiket (a Diagram eszközök / Elrendezés alatt a bal oldalon a legördülő listában tudod kiválasztani név alapján)! Ha ki van jelölve, a Tervezés menüben kattints a Más diagram típus gombra, és a vonalat válaszd. (Az adatsor jobb klikk menüjéből is eléred ezt a Sorozat-diagramtípus módosítása alatt.)
Ne felejtsd ugyanezt megcsinálni a másik adatsorral (bottom) is!
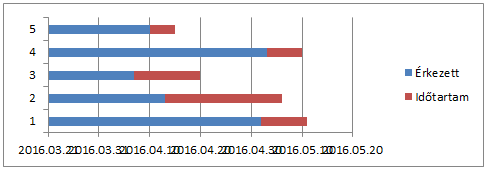
Most így néz ki:
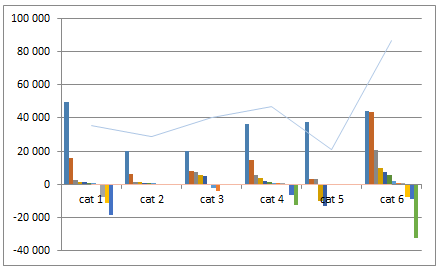
Van egy halvány vonal, és egy másik is, ami nem látszik, mert 0 értékekből áll.
Tudom, ez egy picit macerás lépés – a 2013-as Excelben sokkal könnyebb az adatsorok diagram típusának módosítása – talán ezt szeretem legjobban az új verzióban. 🙂
5. Pozitív/negatív eltérés oszlopok hozzáadása
Most jön a legérdekesebb lépés! Jelöld ki az egyik vonal adatsort, és az Elrendezés menüben az Elemzés csoport alatt megtalálod a Pozitív/negatív eltérés gombot – add ezt hozzá a diagramhoz. (2013-as Excelben: Add chart element / Up/down bar)
Ezek az oszlopok „beülnek” a két vonal adatsor közé:
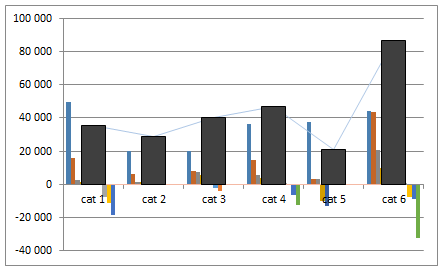
Készen is vagyunk!
Na jó, egy kis formázás még hátravan, de a lényegi rész már felépült!
6. Oszlop szélesség beállítása
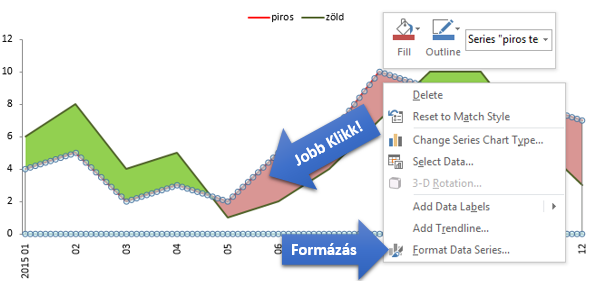
Az igazán szép megjelenéshez az eltérés oszlopok szélességét növelni kell. Ezt kicsit trükkös helyre rakták, nem az eltérés oszlopok formázásánál, hanem a vonal adatsornál találod meg. Jelöld ki a vonal adatsort, és kattints a kijelölés formázására.
7. Adatsor formázások
A vonal adatsort formázd vonal nélkülire – nincs szükség rá, hogy ez látszódjon.
Az eltérés oszlopok különleges helyzetben vannak: ahhoz, hogy a mögötte levő kis oszlopok látszódjanak, ezeket átlátszóvá kell formázni. Teheted teljesen átlátszóvá, és használhatsz csak keretet a megjelenítéshez. Másik megoldás, ha választasz egy színt és az átlátszóságot magasra (kb 80%) állítod. Én egy kombinált megoldást választottam: színátmenetes színezésben adtam meg, hogy az alsó rész teljesen átlátszó, a felső pedig zöld alapszínnel részben átlátszó. Jó ki játék és próbálgatás ez az alsó sávok formázása menüben! (Legegyszerűbben: jobb kattintás az eltérés oszlopokon.)
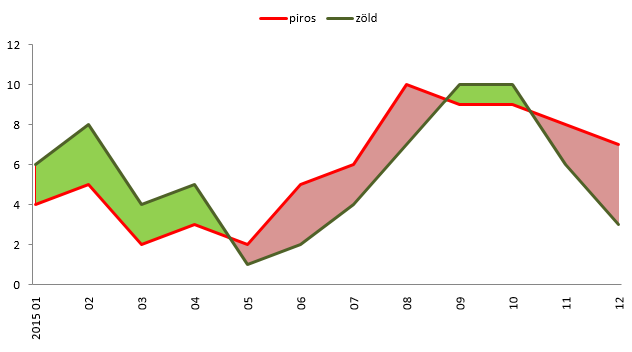
Íme a végeredmény:
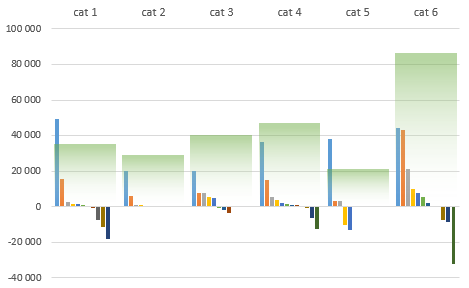
Ha sablonból szeretnéd a grafikont használni, vagy kíváncsi vagy a beállításokra, töltsd le a minta fájlunkat!
Ha többet szeretnél tudni az eltérés oszlopokról, olvasd el a vízesés grafikonról írt sorozat első részét!
 Kérdezz tőlünk Excel segítő csoportunkban vagy kövesd az Adatkertészetet a Facebookon!
Kérdezz tőlünk Excel segítő csoportunkban vagy kövesd az Adatkertészetet a Facebookon!

















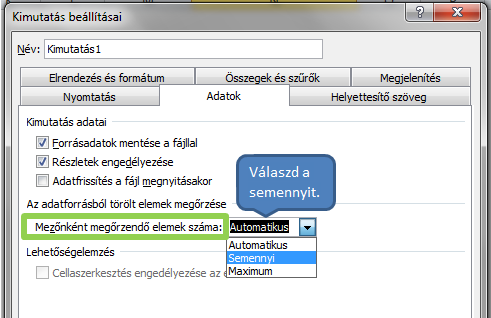

Legutóbbi hozzászólások